

Users need a zero-hype definition of Data Architecture, that can be general (ie, vendor agnostic) or specific (drawn to represent deployment on a specific cloud or vendor platform). They also need terminology, a functional-but-flexible model, and a list of requirements for data architecture, before they can discuss it internally and make objective decisions about it. This podcast provides that framework.
Most data architectures have four broad requirements:
RECAP: In short, a data architecture encompasses many components. But the architecture is more than just an inventory of data assets or a portfolio of database platforms and tools for data management. All those must interoperate in both development and production, plus enable data flows and business processes that span the whole architecture.
A D&A architecture centralizes data and functions for it. Centralization facilitates data sharing, collaboration via data, and the operationalization of high-value tasks like data engineering, data science, and all analytics. Centralization also simplifies the control of data governance, business compliance, and enterprise standards for data and data products. With data and tooling centralized, many organizations also centralize their teams and development processes for data management and analytics.
Podcast #3 will return to some of these bullets, plus others, but in more detail, as it makes a business case and a technology case for data architectures.
David Davis: 00:09
Hello, and welcome to the Dataverse.ai podcast, powered by ActualTech Media. Thanks so much for joining us on this inaugural episode of our new podcast. Before we get started, there’s just a few things that you should know about the event today. We’ll kick it off with what you’re gonna learn. We’ve got a lot to learn on this episode. Of course, it’s all about data architecture. Specifically, we’ll start off with the definition of data architecture, what data architecture is and is not, the three major layers that make up a data architecture, and business and technology benefits. And then finally, you know, the big question, why should you care about what a data architecture is? So let me first introduce myself and then I’ll introduce our expert presenter. My name is David Davis of ActualTech Media.
David Davis: 01:03
I’ll be the host and moderator for the podcast today, and we’re excited to be joined by Mr. Phillip Russom. Phillip has a 25 year background in the IT industry as an analyst, researcher of best practices, managing vendor products, market trends in data management and analytics. He’s worked at most of the world’s leading IT analyst firms, including Gartner and Forrester Research. And now Philip RussOM is a semi-retired industry analyst who applies his long experience with data management and analytics to successfully design and execute a number of different projects, including publications, speaking, short term consulting, and today, our special guest here on the first episode of our new podcast. So welcome so much Philip, it’s great to have you on the podcast. We’re really looking forward to this discussion. I’m looking forward to learning all about the big question of the day— what is a data architecture? Philip, it’s great to have you, take it away.
Philip Russom: 02:16
Well, thank you David very much for the very nice introduction there, and my special thanks to everybody listening. I really appreciate, you could find time in your busy schedules to come with us and talk about data architecture. So I’m gonna start by defining data architecture. So what is it? Well, it’s the data silly? Where did I get that expression? Do you, you remember when bill Clinton was trying to get elected president and I think his campaign manager came up with some key messages for that campaign and the number one priority message for that campaign was, it’s the economy, stupid? And so that phrase has been paraphrased and altered a lot of ways. If we adapt it to data architecture, it becomes “it’s the data, silly,” right? It’s kind of rude to call people stupid.
Philip Russom: 03:05
So I’m just gonna say silly. So the thing about a data architecture, it’s really about the data that’s being collected into the architecture managed there and then served up so that the organization can support many use cases that are data driven. And so it’s not just about the architecture. However, there’s a lot of things in a data architecture beyond the data. And by the time I finish my list, you’ll see, it’s quite a lot of stuff that goes into the architecture—data itself is the priority. The second priority is really data about the data. In other words, metadata. And, you know, metadata’s been with us forever, since the dawn of database management systems and similar data management software. And data management’s even more important than ever because that’s how you find data. You document it, you describe data with metadata, and that allows all kinds of users and tools to interface with that data and access it and reuse it.
Philip Russom: 04:01
And you know, the kind of data architectures I’m gonna describe to you today, they assume that you’re gonna have numerous data sets in this architecture. It’s not one big, solid, monolithic database. That’s not it at all. You can think of a data architecture as being a series of databases, a series of data sets, but they’re all brought together and integrated for common goals. For example, I’ve spent a lot of my career in data warehousing reporting analytics. And so the data warehouse and new things like the data lake, these are architectures that come together to integrate data from many different sources for the purpose of analytics, whether it’s traditional reporting or all the way up to the most leading stuff like data science. So multiple data sets, but typically brought together for some common purpose like that.
Philip Russom: 04:53
Also, the data architecture involves a lot of documentation of data. And documentation, you should think of that as just different ways to describe data. I already touched on metadata, and that’s one way to describe data. There’s also descriptions of data through other technologies and so forth. And you need the descriptions to find the data, but also to do what you really want out of the architecture. You wanna reuse data, re-assess data, many different ways to support multiple use cases. So many types of reports, including newer report styles like the dashboard, many types of analytics, both the old stuff like OLAP and data mining, and the new stuff like machine learning and artificial intelligence and so forth. Soyou need to carefully document data and also the documentation of data helps you to discover relationships across data sets.
Philip Russom: 05:49
A classic example there would be like customer data. See, there’s customer data in your organization in many different systems—say, in your financial systems in sales, marketing campaigns, in things like your call center or tech support center, lots of information about your billing and shipping. I could go on. So you have a lot of data about customers and you know, if you look at customer data in, say, the billing and shipping, and if you look at customer data in your financial apps, then you may think, wow, this is a great customer. They’re spending a lot of money with us. But then when you look at data that came from the call center, you realize, wow, they are really dissatisfied with our products and services and therefore they are on the verge of churning, you know, leaving us. So part of the architecture thing is to bring data from numerous data sets, bring it together for common goal. And also part of that common goal is to discover and understand relationships across data sets.
David Davis: 06:51
Now, Philip, I I’m a visual person. I know a lot of folks out there in the audience are visual as well. When you talk about documenting data relationships, what would look like and how would you go about doing that?
Philip Russom: 07:03
Awesome question. You know, I pointed to metadata and similar things like the data catalogue is one way to document data, but there are others. So let me hit the other ones, for example a lot of analytic tools nowadays actually read a lot of data and say say you’re trying to do machine learning and you have a machine learning tool that is gonna read a lot of data so that it can learn from that data and then create a kind of analytic model based on what it found from scanning a lot of data. And so as that machine learning type analytic application, it scans a lot of data. It’s not just building a prototype analytic model. It’s also documenting what it finds. So for a lot of analytic applications, the scanning abilities also document data as it’s found. Also, we have other things like older tools for data profiling.
Philip Russom: 07:58
They tend to document data as we profile it and that documentation can be shared among many developers, right. And then finally today we’re seeing more and more automation, which proactively goes out, finds data in your enterprise, scans it, and then documents it. And a lot of this technology is using graph analytic capabilities. And you know, if you’re looking at a lot of customer data, you can create a customer map where you see clusters of related customers and stuff like that, but you can also use that very same technology to go out and read a lot of data elements and describe how these di these different elements are related to one another. So so we’re seeing, so right there is quite a list. There are many ways you can document data in ways that help you discover relationships across data sets.
Philip Russom: 08:50
All right. Well, moving on, you know getting back to these data architectures a lot of times people think data architecture. Yeah. That’s mostly about data at rest in storage and yeah, that’s part of the picture, but also most modern data architectures also involve data in motion, say coming through real time interfaces, say coming from a data stream if you’re in the internet of things, lots of devices and machines with sensors on them, et cetera. If you’re in logistics, lots of trucks and vehicles and rail cars, a lot of these things are generating data and sending, sending them into a data architecture like this as the data is created. So it’s not just data at rest in storage. These architectures also have to capture data in motion. Also, these architectures do enable data to move data, to move from wherever it originates into the architecture, sometimes out of the architecture to be used elsewhere.
Philip Russom: 09:55
These architectures also run on a wide range of data platforms and data management tools. And for data platforms, they’re really thinking about database management systems. You know, we call them databases for short. For data management tools, think ETL tools, modern data pipeline tools, but also end user tools for reporting and analytics. So there are a lot of tools involved, but those as I’ll point out here in a minute, those are just part of the picture. And so you know, at the end of the slide here, I have to say a data architecture unifies all the above. So a data architecture has a lot of components, some take higher priority than others. Really the highest priority is the actual data. You can have all this, you can have a wonderful set of tools, but if the data’s not right, then the architecture’s really not gonna give you much value, right? So you have to keep these priorities straight, but realize that the architecture involves a lot of components and also these components need to interoperate with each other. So you’re gonna have multiple tools for multiple vendors and open source, but they do have to share information and actually interoperate when they are in production.
David Davis: 11:03
So, Philip, it sounds like a data architecture does just about everything under the sun there. I mean, is that true? And how do you unify a data architecture?
Philip Russom: 11:13
Yeah. Again, these are very good questions and I can sort of answer those questions by talking about what data architecture is not. And with my voice overall, you know, bring in some of the unification features, for example a data architecture, it’s not a mere software portfolio. You know, sometimes people get even technical users, people who have experience as a data professional, they may get distracted away from the high priority, which is the actual data. And they may be, they may be hands on with so many tools and databases all day. They start thinking those tools and databases are the architecture. No, they’re just part of the architecture. So software portfolio, it’s important. Without these tools, you cannot manage the data of an architecture, but they are only one part of this multi-component architecture.
Philip Russom: 12:02
Likewise you know, an architecture, is not a bucket of disconnected data platforms and tools. One of the ways to answer your question, David, one of the ways we unify a data architecture is to get different tools and platforms within it to interoperate with each other. For example, I mentioned for years, I was in and out of data warehousing. And one of the challenges there is to get your ETL tool and your data quality tool to interoperate. So that as the ETL tool is extracting data, it can show that data to a data quality tool. And the data quality tool has an opportunity to make improvements to the data before the data is then transformed and loaded somewhere else. So, I mean, that’s, that’s a classic one, just trying to get your ETL and data quality tool to work together.
Philip Russom: 12:50
You may also be interoperating with a master data management tool. Sometimes interoperating with some real time data capture tools. And so today more and more users do have solutions where interoperability is the norm. You’ve got all kinds of tools communicating with each other, both in development, but mostly in production. So this interoperability, it’s mostly a production phenomenon. So that helps to unify. That helps to unify the thing. I also mentioned development there, you know, there are all kinds of processes that wind their way across the data architecture, and many of them are development processes. So the way that data engineers develop data products, quite often these have a a process to them that work their way across many components of the architecture, the way that any data scientist or data analyst would work.
Philip Russom: 13:41
They’re usually touching several tools and several data sets. And they do tend to use things that help them unify that. Quite often these same developers rely on metadata as a way of giving them visibility into numerous data sets, giving them visibility into most or even all of the data architecture. So visibility through data semantics is another way to unify the architecture. Also what the data architecture is not, you know, a lot of times people describe a multi-platform environment as a stack of tools. And this idea of a vertical stack is useful, but it’s limited to that vertical slice, a true data architecture also has numerous horizontal processes like the ones I described a minute ago. So a technology stack is inherently vertical. Whereas the data architecture has to be both vertical and horizontal.
Philip Russom: 14:40
And then finally some people say, yeah, we love our architecture, because we can just dump a lot of data in there. And then it’s up to certain users to make sense out of the data and hopefully get some business value of it. I would say, no, that’s not really how you wanna treat your data architecture. One tragic example, we know a lot of data lakes when treated with data dumping do turn into the proverbial data, swamp. A data swamp is where the data was not documented very well as it came in, and it wasn’t curated. We allowed people to bring any data they wanted as opposed to data that’s truly relevant to this particular architecture. So you need careful designs, curation, governance, et cetera to keep your data architecture clean. Otherwise it will turn into a swamp.
David Davis: 15:29
Yeah. I love that analogy of the data lake turning into the data swamp. But I did wanna ask you when it comes to controlling access, what about security issues with some really large and complex data architectures like you’re talking about here, Philip.
Philip Russom: 15:44
Oh great. Yeah. Security is very real for data architecture, the way it would be for any it solution, right? Any IT infrastructure. So for example, what you do not wanna do relative to security—there’s an old habit and it’s a bad one, of giving all developers and also certain classes of tools like ETL tools and search tools—we just give them what’s called CIS admin privileges, which means that those people and tools they can access anything, anytime they want, in any fashion they want. And that’s bad, that’s very bad security. You need everyone and every technical process to be controlled with some forms of security. And in fact, multiple forms of security really are required for all kinds of systems, including this data architecture. So for example, you know, you need fairly traditional username and password.
Philip Russom: 16:42
You need the identification and verification that goes with that and so forth. That’s all good stuff. But there are functions. There are security functions that are particularly useful in a multiplatform multi-tool environment, like these architectures. I’d say top of that list would be single sign on. So you know, the last thing you want is your developers or some tool processes to be stymied by the fact they have to stop every couple of minutes to log into yet another system and so forth. So single sign on is very useful for this kind of environment. Also, role based security is good. You can define roles in terms of which pieces of your architecture, certain roles have access to and which pieces they don’t, right. So you can kind of sort people’s access privileges through roles. And then finally, don’t forget an architecture like this benefits tremendously by security down at the storage level.
Philip Russom: 17:37
And I’m thinking of what’s often called data protection. And data protection, we usually see it manifested as encryption or data masking. And you know, in the old days, encryption was an add-on to a lot of data platforms and it created a performance overhead that could drag down the performance of your system. Those days are gone nowadays. Encryption is baked in to every brand of database, all the latest versions of the older brands. And especially a lot of the newer cloud based databases even have encryption as the default setting—it’s turned on automatically. And you can have encryption without worrying about any performance issues for encrypting and decrypting. That’s very fast, you can depend on it. Also, data masking is a little different, you know, decryption, we quite often will encrypt an entire database or entire tables.
Philip Russom: 18:30
If you wanna be more selective about data, you’re protecting at the storage level, then masking would help you do things like say just mask certain columns within certain tables. And if you think about it, the customer data example is a good one with customer data. You know, most of the data is banal. It’s not sensitive, it doesn’t really need certain protections, but you may have customer data that is personally identifiable information, you know, PII, or it could be sensitive in the HIPAA sense that it’s healthcare information or financial information. So you still want certain users to be able to access that data and do their reporting and analytics work with it. Do whatever operational things they’re trying to do, like you know, develop the next marketing campaign. So you want those use cases to go forward, but you can mask the sensitive columns, and most tools can read values from those, but the end user, the tool user doesn’t actually see that data and the tools will return aggregations. So summations, calculations like averages and means, and so forth. And you know, those inherently make data anonymous, right? So the sensitivity issues go away. So you get the idea, I’m sorry to go on about it, but there’s so much you can do with security. It’s a very rich field today, isn’t it? And all of it applies to the data architecture.
Philip Russom: 19:59
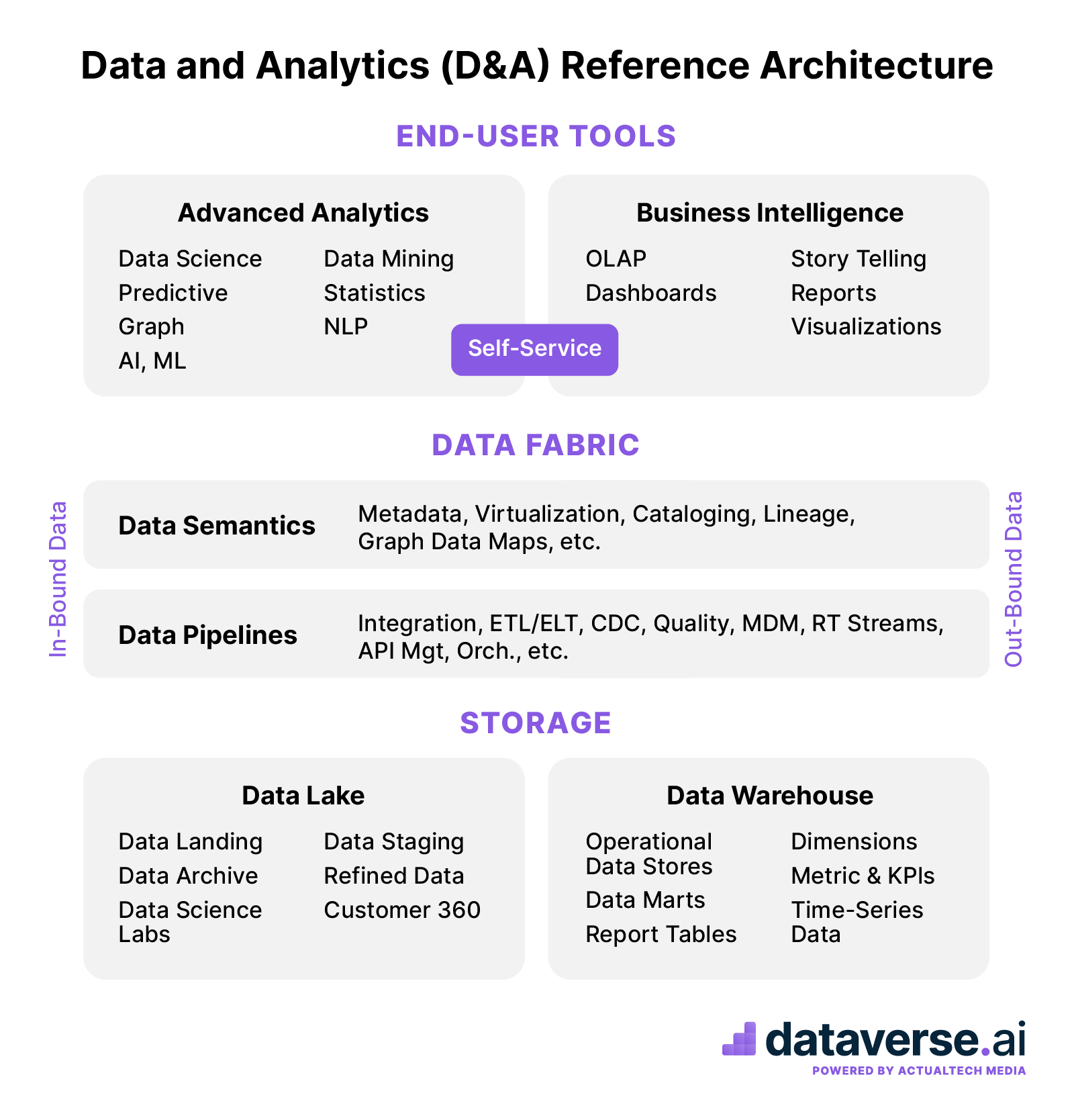
Okay. Well, let’s finish up our definitions around the data architecture by presenting a reference architecture. And I have in mind a data and analytics reference architecture, because that’s what I know best. And I do find a lot of users visualizing this in a particular way. So that’s the way I’m gonna visualize it as well. I’ve actually drawn a graphic here, but if you’re just listening to my voice in your head, you can imagine this reference architecture because really it boils down to three distinct layers within the reference architectures, and each of the three layers of this architecture itself has numerous components within it. So let me go through the three major layers of a reference architecture for data and analytics. And I’d actually like to start in the middle. So if you’re, if you’re drawing this in your head, so think of a layer in the middle of this picture and the layer in the middle, that’s devoted to what has become called the data fabric.
Philip Russom: 21:04
So if you’re new to the data fabric, let me, let me suss it out for you. You know, the data fabric itself has three layers and that right there tells you that quite often architecture has multiple layers and there could be layers within the layers, right? So that’s just the nature of architecture. So let’s go back to the middle layer of this reference architecture for data and analytics. That’s where the data fabric is. And I’m gonna step you through the three layers of the data fabric. So I think most people when they hear data fabric and they know what it is, they think of the layer in there that does traditional data integration. Although today we may call that data pipelining, right? So there’s a layer. We have multiple forms of data integration, ETL, cetera, and things that go with integration, like data quality and mastery management.
Philip Russom: 21:50
Then a second layer in the data fabric is data semantics. And we’ve already talked about metadata and data cataloging, and there are other ways to describe data that are in the semantic layer of the fabric. And then the third layer within the data fabric is a special layer for real time data. See most of the data that’s gonna come into and out of a data architecture like we’re talking about today, it’s gonna move through batch and bulk technologies. And yet there’s some data that’s coming at you in real time. It’s coming from data streams from internet of things, sources through event processing messaging systems, through a variety of application programming interfaces. And to capture that data, you really need a completely different set of tools and technology as compared to bulk and batch. That’s the real point here. So the real time data layer, there are some fancy names for it.
Philip Russom: 22:42
Some people call it the fast lane. Other people call it the speed layer, but so you, you ha typically have one layer for batch and bulk and a second complimentary layer for realtime data. And then the third layer of the data fabric was data semantics, typically metadata and data cataloging. So that’s the middle part of this reference architecture, where the data fabric lives. Now, as data enters the architecture through the data fabric, at some point it’s going to rest in the storage layer, and imagine the storage layer at the very bottom, right? So data fabric in the middle, storage on the bottom, and you know, there are recognizable, you know, sub-architectures in there, for example, the data lake and the data warehouse live in the storage layer. And you could have all kinds of stuff down there as well.
Philip Russom: 23:30
Also, you, you could have layers for… I think, a good umbrella term would be information lifecycle management, for example, how do we manage data as it ages? How do we manage data as its business value changes? And so the most recognizable thing within information lifecycle management, again at the bottom storage layer of our data architecture, the most recognizable thing there would be data archives. So some organizations have multiple archives. You may just have one. Also, to go with the archiving, you need to work out your retention policies, you know, what are the rules for how long we keep data, if it gets to a certain age if the number of data accesses drop off to a certain level, we’re probably gonna move it to this lower part of the architecture, and, you know a lot of storage subsystems on-premises, but especially storage on cloud are naturally partitioned into hot and cold layers.
Philip Russom: 24:27
So hot is where you keep the most frequently accessed data, and that’s the most expensive storage. Whereas cold is cheaper, usually slower storage layers. So you get the idea—at the bottom of our data architecture is quite a few storage structures. So the data lake, data warehouse, and then data archives and related stuff, we’re almost done. So let’s finish building up our reference architecture by going all the way to the top. And that third major layer up at the top of the architecture, that’s where end user tools are. That’s where human beings come into play, and they’re consuming data that’s delivered to them typically through traditional business reports or some variations of that, like management dashboards, maybe you know, older stuff like online analytic processing, a lot of visualization tools are there also up at the top layer of the architecture with in user tools. We have stuff that’s more advanced type of analytics, right?
Philip Russom: 25:25
So that’s that’s where we see the data scientists and a lot of data analysts working. And there nowadays the modern data scientist is using machine learning and artificial intelligence as a way of developing predictive analytics applications. Right. So to finish this up again, draw it in your head—three major layers within the data and analytics reference architecture, the data fabric in the middle. And I think of that as pretty much the backbone. That’s why I put it in the middle. So data coming into and managed within the reference architectures, usually handled by the data fabric in the middle of the architecture. It invariably interoperates a lot with storage down at the lowest level of the architecture. And that’s where your lake, warehouse, and archive live. And then finally up at the top, that’s where you find people consuming data that’s delivered to them typically through a variety of reports and analyses.
David Davis: 26:24
Wow. Philip, this is really kind of mind blowing here. I’m sure a lot of folks out there just, you know, consume the data from the end user tools and never even envision, you know, everything that goes into a modern data architecture. Yeah. So, I mean, given the size and complexity and the risk and cost of creating such a large, you know, data architecture, why are organizations still building these?
Philip Russom: 26:48
Yeah, that’s a great question. And yeah, once people see the list of what could potentially be in an architecture, I mean, let’s be honest, in the real world most architectures end up being a subset of what I’m explaining here. I’m just trying to be complete, but it’s still daunting, isn’t it, it’s really daunting. I hope I can help people who are data architects, or they’re aspirationally hoping to become an architect, right? So you know, I hope you can use what I’ve drawn here and understand, you know, what the possibilities are for this, but to come back to your question, David, why would an organization wanna put themselves through this? There’s a lot of time, risk, and cost associated. Well, I tell you, they do it for the benefits. There are benefits to the data architecture that I’m describing here, and the benefits fall into two very large classes.
Philip Russom: 27:38
There are a lot of benefits that directly go to the business business. People see certain things they can do with data, especially analytics through this kind of architecture, but also for the technical people, especially data management folks and analytic specialists. They see a lot of technical benefits. For example, the potential benefits for the data architecture from a business viewpoint are really addressing a common problem that we all struggle with. You know, the real problem is that the data in a modern enterprise is distributed, and with data being strewn across so many source systems, many applications, databases, your organization’s generating a lot of it, partners and third parties are generating it. It’s a lot of data in many different locations, and that inhibits business activities that rely on data that comes from many sources, but has to be brought together and integrated before that actual business use can be done.
Philip Russom: 28:35
Right? So so distributed data is the problem. And the architecture does address that problem by bringing data together in a shared, typically centralized data architecture. And this enables tremendous data exploration and discovery. I don’t know if you realize it, but more users and user types are exploring data than ever before. And a lot of this is because there are business people who know enough, especially about the relational paradigm, that they can form their own queries. They can design their own tables and they can build their own fairly rudimentary data sets. And once they do that in a self-service fashion, they can move on to doing data visualization and maybe some light analytics as well. So exploration and discovery, that’s fundamental to what a lot of business people want to do, which is self-service access, right?
Philip Russom: 29:31
So another thing is sharing of data. And we do see a lot of businesses sharing data more than ever before. You know, quite often it’s people in the chief officer’s camp, sometimes the CEO who says, look, we see innovation happening in this business unit, but these other business units don’t even know about it, much less leverage the innovation of their peers. So sharing data, sharing applications and stuff like that, that’s kind of a big deal in a lot of organizations nowadays, to share innovations and share approaches to different solutions, but also certain data really should be shared. A classic example would be customer data. There’s so many customer touchpoints within your organization that those those different business units, departments, and applications need that data. Also bringing data together in one place, the way these architectures do.
Philip Russom: 30:24
You can have richer analytics simply because you’ve got more data from a wider range of viewpoints, right? This also gives you a richer reporting. There’s an increase in the number of reports to where one report has data that comes from many different sources. And those are typical of reports that people at the high point of the organizational chart, you know, people who are at the VP and director level, most of their reports bring data together from many sources. So for them to have visibility they need through reporting into a great deal of activities in the organization. They need this architecture. And then I’m gonna skip to the final bullet here, which is about governance and compliance. You know one of the benefits of these centralized architectures is that when you get data in fewer places, it’s fewer locations, fewer systems to secure and fewer systems to govern in terms of data access.
Philip Russom: 31:18
So there really are quite a few benefits there. Technical benefits are a little different, but they do address the same problem, which is distributed data. So distributed data presents different problems for the technical user as opposed to the business user. But there are likewise benefits. So a lot of times when user organizations design this kind of centralized and shared data architecture, as they design it, they design data consolidation into it. In other words, they’re not just gonna copy data from 17 different systems. They’re gonna consolidate the data so that there are not 17 data sets in the architecture. There’s gonna be a much lower number. So data consolidation tends to simplify things, especially people doing reporting and analytics, data warehousing, managing the data lake. So consolidation has some things there, you know, sometimes you can’t really consolidate data physically.
Philip Russom: 32:12
So there are ways to create virtual layers that make the data look like it’s consolidated at the storage level, but it’s not really, it’s just consolidated at the virtual level. Centralization does tend to simplify things like ingestion of data into some of the sub pieces of the architecture, like getting data into the warehouse is a lot simpler when a lot of the data of the warehouse needs nowadays is already in the data architecture, quite often in the data lake. See what I mean? So a lot of things like that get simpler for an architecture like this, you know… architects don’t just design data models and models that spanned multiple data sets. They also tend to define standards for data and that sort of thing. So as the architects design these new data architectures, they often are creating enterprise data standards or revising older standards as they work.
Philip Russom: 33:11
Also a lot of people are migrating to cloud. And so part of the question is, as we move our data and our solutions, move our people and our applications to cloud, what are we migrating to? And yeah, one of the questions is if we’re gonna migrate data to a cloud, what’s the cloud architecture gonna look like? So that’s one of the reasons data architectures became important in recent years. There’s so many migrations to cloud, and how can you migrate data to cloud if you’re not sure what the structures are on cloud? So you need to design your new data architecture on cloud before you start planning the migration. And then, finally, you know one of the things about these centralized and shared data architectures is they give everybody greater visibility and data observability because of the unified architecture. That’s true not only for the business, people who are trying to govern data, but it’s also true for the technical people who are trying to develop new data products. Right? So those are other benefits that come from this. So I mean, yeah, go ahead.
David Davis: 34:16
Philip, I mean, there’s so many benefits here. You’ve outlined there, especially being a technical person, myself, you know, consolidation, centralization, standardization, migration to the cloud and visibility and then you covered a ton of business benefits as well. These I know are kind of high level, I’m wondering, can you give us some examples of how this actually plays out in the real world?
Philip Russom: 34:38
Yeah, exactly. And I think I can answer your question, but also answer the older question, which was why should you care? Why should you care about this data architecture? Well, you care about it because of those benefits, but also those benefits do work their way into very specific use cases, right? So when the rubber hits the road it’s the general stuff is good, but when the rubber hits the road, it has to do so in very specific use cases. So let me talk through some use cases here at the ending of our talk. And I have prioritized this list based on what I think business people tend to get excited about, right? Not just the technology people, but the business people as well. So why you should care really is because these these new types of data architectures really do enable advanced analytics in a way that we just haven’t been able to do before, you know. Data, for example, data science has been with us for years and data science is a use case, but data science is pretty challenging because it really varies a lot from one data science project to the next.
Philip Russom: 35:51
And so the this modern data architecture brings a lot of data together for what the data scientist needs, which would be large volumes. They typically want data from many sources, so they have as wide a range, they just have more data viewpoints, and the viewpoints come from more business functions instead of just one. And we talked about that a little earlier. So for the kind of discovery oriented, lots of analytic correlations that the data scientist does, this architecture gives that stuff. But that sounds like a techy benefit, doesn’t it? So that techy benefit leads to what the business people want, which is more forms of analytics. We’re still doing older forms of analytics. Like everybody’s done OLAP and some data mining and some statistical analysis, and those still have value, but what, what business people really want.
Philip Russom: 36:44
And this is uniquely enabled by data science on a new architecture. What a lot of people really want is predictive analytics. And you know, a lot of the buzz and the it press is about machine learning and artificial intelligence. And they sometimes forget to tell you, oh, by the way, those are really stepping stones. Those help you build the components, which then go into predictive analytics applications, right? So from a business viewpoint, one of the biggest advantages and unique ones is that these kind of modern architectures get the business to predictive analytics. You know, we’ve all been driving the car by looking in the rear view mirror and seeing what happened in the past. So a lot of business managers want to be able to look through the windshield and see what’s coming. And that’s, that’s predictive analytics. I’ve talked about self-service a number of times.
Philip Russom: 37:35
And a lot of times it’s the business people who are demanding self-service. Any kind of new stuff you build, they will step in and say, but what about self-service for business people? We really need that. What are you doing for it? And so yeah, most data architecture designs nowadays do create data sets and areas within the architecture specifically for self-service. And a lot of this is very appealing to the business people, but don’t forget, self-service, it’s not just for business people. There are a lot of technology people where sometimes they just need a quick and dirty read of data before they dive deep into a new new project. So self-service can also be for the technical use point. Even data scientists use self-service to get a quick read of data when they get a new analytics project. Also data exploration for business and technology people.
Philip Russom: 38:23
I talked about that earlier, people are exploring data like crazy, like never before because there’s a lot more data. But also we have a better understanding of how to get from data exploration to something actionable. Self-service helps the business person do that. And also the framework for data science that these new architectures provide help other more technical people get from data exploration to more of a data product. Also, you know, real time data is a business opportunity. If business people can see what’s happening in certain business processes within a few seconds of it happening, then they’ve got a much better chance of leveraging that very recent event, or if it’s a problem, they have a much better chance of fixing it immediately. Realtime data is just exploding.
Philip Russom: 39:15
I think part of it is logistics. If we think about how logistics really is kind of messed up, you know, the supply chain’s a little messed up at the moment, but we’re really trying to understand it better. And one way is to understand the current state of of the supply chain by looking at realtime data that logistic systems inherently produce. Right. And so the the collection of data from logistics, that is one of the big spikes in data, data usage nowadays, and all kinds of people are salivating at that. But, you know, real time’s not just for logistics. I spent years working in manufacturing. So if you can get real time data about what’s going on with new supply lots as they enter the manufacturing floor, you can spot bad lots very quickly and react to them very quickly.
Philip Russom: 40:05
And then also you can monitor applications on the shop floor in real time to see, are we on track to meet our service level agreement? We agreed to produce X number of widgets today, are, are we meeting our production yield promises and so forth. So a lot of great uses for real time data. And then I mentioned data sharing across business units. That has become, that sounds general, but that has become a use case. And especially database vendors and cloud vendors even have data sharing products today. Data semantics is in a lot of ways an enabler, and yet there’s certain use cases where you’ve gotta have really good data semantics. A lot of businesspeople are looking forward to the data catalog and data catalogs. There are different ways to build a catalog, but most of them are built on somebody else’s data semantics, right? So the data semantics for the catalog, a lot of people are doing that. And we’ve talked about how governance gets simpler as do a variety of things like multi-data-source reports. So you get the idea here in the real world. A lot of those benefits of the modern data architecture do manifest themselves in high value business use cases.
David Davis: 41:23
Well, Philip, this has been so excellent. I’ve learned so much about data architectures, you know, what they are, what they’re not the layers you went into, great detail on, you know, what makes up a data architecture, and then you covered the benefits, both the business, as well as the technical. And then now the use cases for a data architecture. This has really been, I think, an excellent, excellent foundation for our upcoming episodes. We’re gonna be learning more about data architectures and diving deeper into data architectures. So thank you so much for the excellent education today. Philip. I appreciate it.
Philip Russom: 42:02
Yeah, you’re most welcome. And thank you for giving me an opportunity to talk about something I really deeply care about, and I think is really important, namely data architecture.
David Davis: 42:12
Absolutely. Yeah. This is gonna help so many companies out there. So many technical and business people who wanna learn more about data architectures and really use them to, you know, power their business and really do some amazing things. Some great examples you provided here on the episode today. So again, thank you to our expert, Philip Russom, thank you to everyone out there in the audience for joining us on the podcast today. If you haven’t already, make sure that you subscribe to get upcoming episodes of the Dataverse.ai podcast, you’ll find it wherever you subscribe and listen to your podcast content. I look forward to our next episode. I’ll see everyone there and we are excited to have you back Philip. Thank you to everyone and have a great day.
