

When it comes to Business Intelligence (BI) products, most of the reporting tools in the space presume that your organization has a data warehouse in place.
A data warehouse is most commonly a relational database with data ingested from transactional systems (also known as online transaction processing, or OLTP, systems) on a regular cadence or even in real time.
The action to ingest the data into a data warehouse is called an extract, transform, and load (ETL) process. ETL processes were traditionally run daily, but modern data demands typically require them to be run more frequently—in some cases, even streaming real-time data into the data warehouse.
Business analysts, data engineers, and organizational decision-makers access this data using BI tools like Power BI, Qlik, and Tableau, along with other analytical applications that make use of the data.
The Star Schema
Data in a data warehouse is commonly organized into tables within a single database. At the core of most data warehouses is a “star schema,” in which data is organized into “facts” and “dimensions.”
Facts represent quantitative pieces of information, like a sale or a website visit. These fact tables have foreign key relationships to dimension tables. Dimensions are related to the facts and describe the objects in a fact table. A sample star schema is shown in Figure 1.
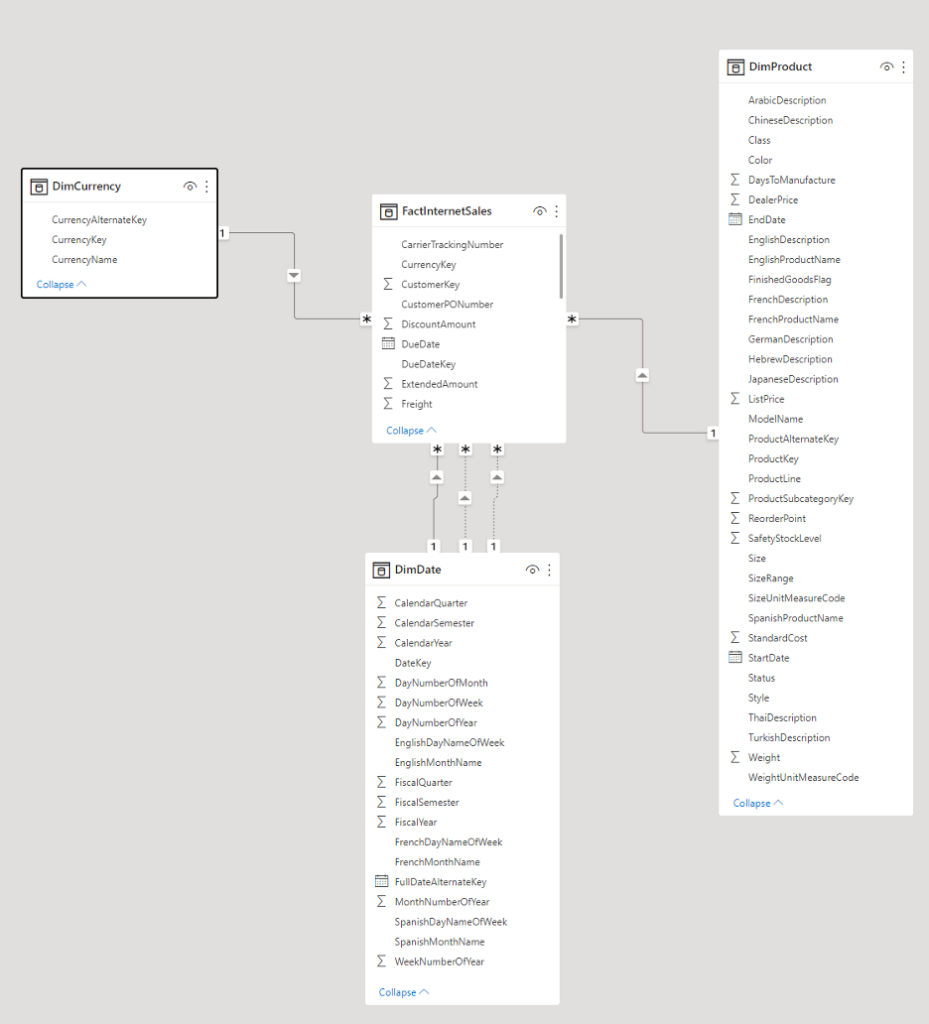
This data model (also known as a dimensional model) is very efficient for queries that read data—most data warehouses also optimize for the bulk loading of fact data.
Data warehouses are known as online analytical processing (OLAP) data structures, as opposed to OLTP databases. This structure is a trade-off, which comes at the expense of storing redundant data in this structure (keys are stored in both fact and dimension tables) as part of this denormalized design. The queries against the dimensional model are simpler (fewer joins), and many metrics are simple aggregates (sum, average, maximum) of columns in the fact tables.
Dimensions which are loaded less often are also designed to deal with changes in data over time. Some examples of this include names of places, customers, or products. This concept, called “slowly changing dimensions,” allows for queries to historically analyze data while considering description changes.
While there are other types of schemas used in data warehouses (for example, the snowflake schema), star schemas make up most data warehouse workloads.
Since by its nature the data warehouse aggregates data from a variety of systems, its databases can become very large. Most data warehouses are terabytes in size, and it’s common for them to reach 50 TB or more. This can require a great deal of processing power, so many data warehouse systems use scale-out approaches to improve query performance. On-premises systems include Teradata and Netezza, while cloud offerings include Amazon Redshift, Azure Synapse Analytics, and Snowflake.
The systems all distribute fact data across multiple compute nodes, allowing aggregations to receive help from massively parallel processing (MPP). While the MPP products draw a lot of attention and marketing dollars, most data warehouses run within a single server.
Data Warehouse vs. Database, Data Lake, and Data Mart
These terms are often used interchangeably, and many products in the space support using all the terms. Here’s a breakdown of each one.
Data Warehouse vs. Database
Most data warehouses are built on top of relational database engines (RDBMS), which are commonly referred to as database servers. While some NoSQL solutions are not built on an RDBMS, most data warehouses operate as a database on an RDBMS.
The other confusion that sometimes comes into play is referring to databases in the sense of OLTP systems only. This is inaccurate—if your data store has tables and runs on a RDBMS, it is indeed a database.
Data Warehouse vs. Data Lake
This distinction gets a little bit more confusing because most modern data warehouse systems support ingesting data from a data lake.
A data lake is typically an object store (think Amazon S3 or Azure Blob Storage) into which substantial amounts of files get written. Unlike a data warehouse, a data lake does not have predefined schemas.
Some data warehousing systems are built around data lake—Databricks is good example. Other data warehouses support ingesting data from the data lake through the ELT process. Typically, “external” tables (which are only metadata objects that don’t store any data) get created in the data warehouse. From those external tables, data is ingested to regular tables within the data warehouse.
Data Warehouse vs. Data Mart
A data mart is also a dimensional model, but it represents a subset of the total data warehouse. Typically, this data is related to a single line of business, department, or geography. Since a data mart deals with a smaller data volume, it allows the team to run more in-depth queries over the data without impacting other users. The main difference between a data mart and data warehouse is that the scope and size of the data is much smaller in a data mart.
Data Warehouse Benefits
The biggest advantage of having a data warehouse is that it puts all your business’s data in a single data store, providing a single version of the truth.
This is important because reporting against operational systems is challenging in terms of both performance and data quality. While real-time reporting has it uses, reporting queries can block sales transactions, or show pending transactions that may be cancelled. Beyond those challenges, OLTP schemas are designed to optimize writing data rather than reading it.
Having a simplified star schema is good for both query performance and organization—and they are well understood by business intelligence tools, which makes things easier for business analysts.
The structure also provides very good query performance, even as data volumes ramp up. This has been helped by the adoption of column storage for most fact tables, but even older versions of data warehouses performed efficiently.
Data warehouses also allows for including data quality and master data services as part of the data ingestion process, which results in better data quality. All of this means your business users can get faster, better answers which can lead to actionable insights and a healthier bottom line.
Better Outcomes
Data warehouses large and small are at the center of most business intelligence architectures. By offloading reporting from operational systems into a read-optimized system that’s easy for analysts and data scientists to query, your business can make better decisions. In addition, the performance optimizations and scalability available through MPP data warehouses mean that no matter how much data you have, the data warehouse can meet your performance needs.
