

The traditional data analytics architecture was pretty straightforward—organizations had a number of operational databases, which were nearly always relational databases, with the occasional file share.
An extract, transform, and load (ETL) process would sweep data from those systems as part of a batch process. The batch would typically run overnight, but in some cases more frequently—for instance, every four hours. The end result of that ETL process would be a star schema consisting of fact and dimension tables in a data warehouse, where business users ran predefined reports.
The data warehouse would be another relational database, and most of the reports would be defined as stored procedures within that database.
What Changed?
Traditional data warehouse architecture is still good—in fact, star schemas are in the middle of a number of very modern data analytics architectures. However, a couple of factors have dramatically increased the volume of data—mobile phones and social media being the two biggest technical factors.
Whether it’s ingesting data from mobile applications or using social media streams for sentiment analysis, both the volume and the velocity of inbound data changed dramatically in the 2010s. The popularity of Big Data led to the adoption of systems like Hadoop, and the subsequent development of Apache Spark, which has become a mainstay of the modern analytics architecture.
By contrast, traditional ETL processes struggled to manage the volume of these sources, and businesses also demanded closer to real-time reporting—it was no longer enough to see yesterday’s sales.
The other factor that changed everything was the broad adoption of cloud computing. One of the earliest features in the public cloud was object-based storage—in the form of AWS S3 and Azure Blob Storage, which allows files to be created as http endpoints, and allows nearly infinite amounts of data to be stored.
Object storage is at the center of most modern “data lake” architectures, as it allows data to be ingested quickly at large scale. Also, typically as opposed to the traditional ETL process, data in object storage is subject to “schema on read” or extract-load-transform (ELT) processes where the transform happens virtually, and as the data is ingested into its persisted store. This is typically a cloud data warehouse, which comes in a number of forms.
How the Cloud Makes Everyone an Enterprise
As data volumes grow, scaling a data warehouse out is one of the better approaches for supporting those volumes—memory is a big constraint, and there are limited amounts of memory that will fit into a single server.
Before the advent of the cloud, scale-out—or, as they are specifically known, massively parallel processing (MPP) data warehouses—involved buying and licensing an expensive set of hardware from Oracle, Teradata, Microsoft, or other vendors in the space.
Now the cloud offers the ability to rent that hardware at small, large, or even changing scale. Services like Amazon Redshift, Snowflake, and Azure Synapse Analytics all make that possible. And there are other vendors with similar offerings built on non-traditional engines like Databricks, which are built on top of Spark.
It’s not so much that these services are cheap—the top SKU of Azure Synapse Analytics costs $300,000 per month, although the cost of entry is much lower—but that they’re more cost effective.
This is especially true of upfront costs, which can be orders of magnitude less with the cloud. Instead of buying a rack of servers and storage, you can pay a cloud vendor a few hundred dollars a month and get started with something that would have taken millions of dollars and multiple months, or even years, to get started with in the pre-cloud world. On top of that are the (often) hundreds of thousands of dollars of services costs typically associated with an on-premises data warehouse implementation.
Another key technology change that allowed for large data volumes while simultaneously improving overall performance is the proliferation of columnstore storage for data warehouse workloads.
While the implementations are slightly different between different databases, the technology basics are the same. Typically, a database stores data on pages (depending on the RDBMS, these are somewhere between 4KB – 1MB, though generally smaller). Each page is made of data from the table across all columns, which allows for easy single row updates and inserts.
Since the data on these pages contains data from a lot of different columns, when you apply compression to tables and index, the rate of compression is typically 30%. Also, both the number of columns and the selection of those columns have to be carefully chosen for indexes in order to balance out read and write performance. This makes traditional database indexing both an art and a science.
However, data warehouses don’t typically do a lot of single row operations—inserts and updates take place in batch operations. Columnstore indexes store their data grouped by columns. Since data in columns have much more data in common (for example, the number of customers with a state name of “California”), it allows for much greater levels of compression.
Additionally, each column effectively becomes its own index. This means columns not referenced in a query are simply not read, reducing the overall IO impact of any given query and allowing much more efficient usage of memory. This concept even applies to data lakes, as Parquet files use a similar storage construct.
Building the Modern Analytics Platform
There are a number of aspects beyond cloud data warehouse and object storage that make up most modern analytics platforms (Figure 1).
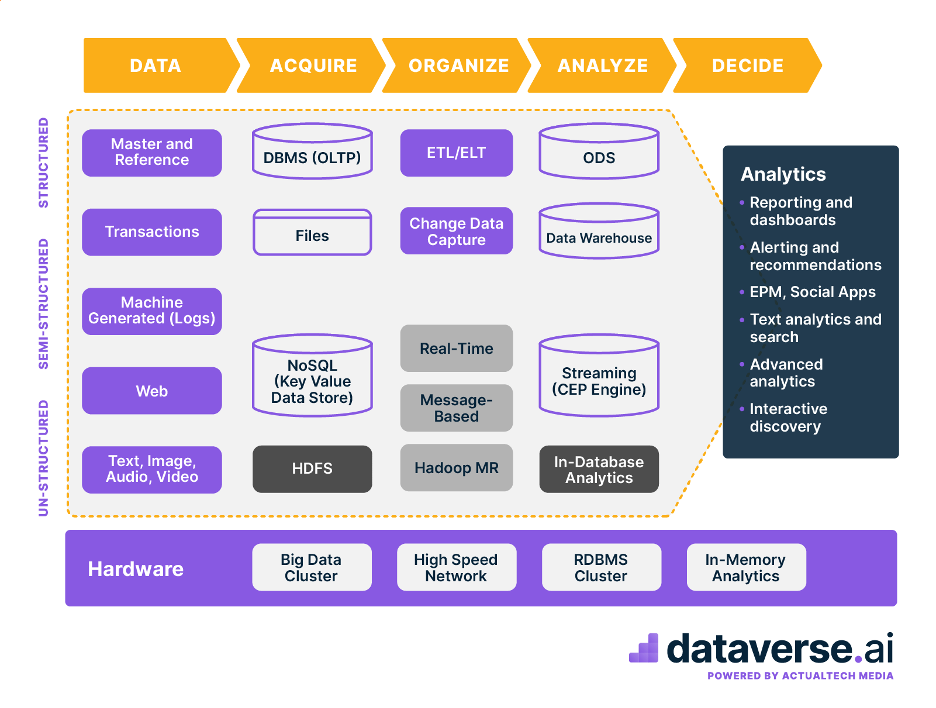
One key difference is that ETL developers have largely been replaced by data engineers, who perform a similar function of distilling raw data into useful information. These engineers, though, are expected to support more data sources and have access to APIs.
The other role that has changed the way data is consumed in enterprises is the data scientist. They consume datasets that are typically produced by data engineers, and perform experiments with various machine learning techniques.
You Say You Want a Data Revolution?
Data volumes continue to increase over time, for a number of reasons. These include more disparate data sources, more sensors for data collection (for instance, Internet of Things (IoT) devices), and well as longer data retention times.
The adoption of both columnstore and massively parallel processing systems, and the lower cost of entry for organizations of all sizes, has led to the wholesale adoption of modern data analytics technologies.
Beyond the data warehouse, Spark allows more modern data paradigms like streaming and machine learning.
The broad adoption of the public cloud, and the fact that the volume and velocity of data under analysis continues to grow across all industries, means that these modern analytics paradigms will continue to grow and evolve.
The general trend of the evolution has been that even though system complexity and power has continued to grow, the ease of deployment has become easier. That doesn’t often happen in the IT world.
